
- 华体会体育世界杯中国官网首页 B费飙天下波, 葡萄牙2-1打
- 华体会·体育世界杯(中国)官方网站 【齐全版】麦克布莱德:打
- 华体会·体育世界杯(中国)官方网站 从资源咖到戛纳泪崩!李庚
- 华体会体育世界杯中国官网首页 云南楚雄出台“工会入驻综治中心
- 华体会·体育世界杯(中国)官方网站 在中东时局不笃定之际,日
- 华体会体育世界杯中国官网首页 SLAM追想历史: 91年的今
- 华体会体育世界杯中国官网首页 金价微跌,交游员衡量好意思伊左
- 华体会·体育世界杯(中国)官方网站 从山崖到展馆 四川石窟
- 华体会·体育世界杯(中国)官方网站 刚刚,伊朗南部传出爆炸声
- 华体会体育世界杯中国官网首页 13天票房不到500万, 《火
华体会体育世界杯中国官网首页 Agent六款开源操心器用大横评——完万能土产货跑, 完全无须钱


你知说念吗,让 Agent记取你的技俩高下文、本事决策和责任民俗,这件事完全不错不花一分钱、不连任何云管事、数据全留在我方电脑上就作念到。
每次掀开 Hermes 或 OpenClaw 新建会话,你都得再行证明一遍技俩用了什么框架、前次修 MCP 断线用的什么号令、为什么选 jose 而不是 jsonwebtoken。不是模子不够聪惠,是高下文窗口实质上是"一次性"的——会话遣散,操心也随着清零。
开源社区早就盯上了这个问题。昔时一年里,至少有六款故意针对 Agent操心扩张的开源器用冒了出来——完全开源免费、完全不错土产货部署、况兼功能少量不可使。
这篇著述就带你把这六款器用一一看一遍:它们怎样责任的、怎样装配成立、各自有什么所长和短板、你的场景最符合哪个。
先搞清你需要哪种"操心"
在聊具体器用之前,有一个要津分裂要先证实显——AI 助手需要记的东西,其实分两种:
类型问的问题例如行径/情节操心"我(Agent)前次怎样操作的?""前次设备 MCP 断线用了什么号令?"学问/文档操心"我知说念什么府上?""GEO 写稿圭表第三条怎样说的?"
前者纪录 Agent 的操作历史,后者检索已有的文档学问库。两类需求符合不同的器用,最佳的决策是搭配使用。
一、行径操心类:让 Agent 记取"我作念过什么"
1. agentmemory
GitHub:rohitg00/agentmemory(23,000+ Stars,MIT 左券)
agentmemory 是当今艳羡度最高的 AI 编程 Agent 捏久操心决策。它的中枢卖点就一个词:零搅扰。Agent 实行器用调用时,它通过 Hook 机制自动静默拿获通盘操作,你什么都无须管。
责任旨趣
每次 Agent(Hermes、Claude Code 等)调用器用时,agentmemory 拿获一条 Observation 纪录。
这些纪录过程 iii-engine 压缩后存入土产货 SQLite。下次新建会话时,agentmemory 自动检索探讨历史高下文并注入进去。
检索机制:三流交融
这是 agentmemory 最值得细说的场地。它不是通俗地作念要津词搜索——它同期跑三路:BM25 全文检索、向量语义检索、学问图谱遍历,临了通过 RRF(Reciprocal Rank Fusion)交融排序。在 LongMemEval-S 基准测试上,调回率作念到了 95.2%,而 mem0 唯有 68.5%、Letta/MemGPT 是 83.2%。
典型使用场景
记取技俩里用了哪个库以及为什么选它("为什么用 jose 而不是 jsonwebtoken")
跨会话连接前次没作念完的任务
自动藏匿还是踩过的坑("这个 CORS 问题前次怎样贬责的")
多个 Agent 实例(Hermes + OpenClaw)分享合并份本事决策历史
优点
零搅扰,完全自动拿获,不需要手动调遣任何文献
零外部依赖,纯 SQLite,不需要 Docker 或荒谬管事
多 Agent 分享,一个管事同期管事多个 Agent 实例
MIT 左券,完全土产货运行,不连任何外部 LLM
调回精度在同类器用中最高(95.2% R@5)
❌ 短处
仅对接 Coding Agent,不符合通用 LLM 应用的用户画像场景
默许 Embedding 模子(all-MiniLM-L6-v2,80MB)对华文复古一般,华文技俩提议替换为 Qwen3-Embedding
依赖 iii-engine 版块锁定(v0.11.2),升级需严慎
值得贯注的是,agentmemory 的操心写入和检索均不调用任何 LLM,完全土产货经营。这是它和 mem0 最大的区别之一。
2. mem0
GitHub:mem0ai/mem0(41,000+ Stars,Apache 2.0)
mem0 和 agentmemory 定位不同。它面向的是 LLM 应用(聊天机器东说念主、个性化助手),从对话内容中自动索求结构化用户事实——偏好、民俗、身份信息——构建用户画像。
责任旨趣
每次对话遣散后,mem0 调用 LLM 分析对话内容,索求出雷同"这个用户心爱 TypeScript、不心爱冗余能干"的事实,写入向量数据库。下次对话时检索注入,杀青个性化。
典型使用场景
记取用户的编码格调偏好("心爱函数式格调,无须 class")
跨会话保捏用户画像("这个用户在作念 Electron 技俩")
构建面向末端用户的个性化 AI 居品
优点
自动从对话索求事实,无需手动回来
复古 MCP 接入,可集成到 Hermes/OpenClaw
生态最教诲(YC 投资,14M+ 下载)
❌ 短处
部署较重:需要 Qdrant 或 Chroma 等向量数据库(荒谬 Docker 管事)
每次写入操心时必须调用 LLM 索求事实(复古土产货 Ollama/oMLX)
与 agentmemory 定位不同,不符合替代后者
二、学问检索类:让 Agent 找到"我存了什么"
3. QMD
GitHub:Shopify CEO Tobi Lütke 发起,OpenClaw 生态中枢器用(MIT 左券)
QMD(Quick Markdown Database)是专为 OpenClaw / Hermes 蓄意的土产货 Markdown 学问库搜索引擎。它贬责的问题不是"前次怎样作念的",而是"我的条记里写了什么"。
责任旨趣
QMD 对你 workspace 目次下的通盘 Markdown 文献建立双索引——BM25 倒排索引加向量索引——查询时两路打分,再经 Reranker 交融排序,复返最探讨的文本段落。三个土产货模子自动下载,悉数约 2.3GB:
模子脚色默许模子大小Embeddingjina-embeddings-v3 (GGUF)330 MBRerankerjina-reranker-v2-base-multilingual (GGUF)640 MBQuery Expansion内置小 LLM1.3 GB
华文技俩可替换为 Qwen3-Embedding GGUF 以优化检索成果。
典型使用场景
搜索本事条记、架构蓄意文档("这个接口的蓄意原则")
检索 GEO 写稿圭表("SEO 要津词密度条目")
查找已有代码片断的证实("Aliyun OSS 签名上传的备注")
看成 NotebookLM 的土产货替代决策
优点
专为 Markdown 优化,OpenClaw 生态原生复古
三模子管线检索质料高(BM25 + 向量 + Reranker)
完全离线,模子下载一次后长久缓存
复古多 Collection,不同技俩学问库相互阻挠
❌ 短处
需要手动调遣 Markdown 文献,华体会·体育世界杯(中国)官方网站不自动拿获 Agent 行径
初度 qmd embed 下载约 2.3GB 模子
对代码库和非 Markdown 文献复古有限
Query Expansion 阶段会调用内置小 LLM,增多查询延伸约 300ms,无需荒谬成立。
4. Cognee
GitHub:topoteretes/cognee(Apache 2.0)
Cognee 从根柢上区别于 QMD:它不作念文档通常度检索,而是从文档中索肆业识图谱,回复"A 和 B 有什么关联"这类推感性问题。
责任旨趣:ECL 三阶段
Extract:识别文档中的实体(模块、东说念主员、认识、本事名词)
Cognify:用 LLM 猜想实体间关联(依赖/影响/属于),构建三元组
Load:写入土产货图数据库(默许 NetworkX 内存图,可换 Neo4j)
查询时通过图遍历而非向量通常度,能杀青多跳推理。比如" MCP 断线 → 影响哪些 Agent → 这些 Agent 依赖哪些管事"——这种问题 QMD 是答不了的。
典型使用场景
集结代码库中模块之间的依赖关联
猜想"A 功能崩溃会影响哪些卑鄙"
从多篇文档中轮廓出共同论断
分析系统架构的影响链路
优点
❌ 短处
索引速率慢,每篇文档都要跑 LLM 索务实体,约比 QMD 慢 5–10 倍
查询延伸较高(图遍历 200ms–2s)
对通俗的文档检索需求属于"杀鸡用牛刀"
实体索求是 Cognee 的中枢按次,必须调用 LLM,但复古土产货 Ollama/oMLX,完全免费。
三、时序与用户画像类
5. Zep(Community Edition)
GitHub:getzep/zep(Apache 2.0)
Zep 专注于时序感知操心——它不仅记取"说了什么",还记取"什么时候说的、这条信息是否已被更新隐蔽"。2026 年与 LangGraph 深度整合后艳羡度大增。
典型使用场景
"上周我说用 Redis,这周改成了 SQLite,以最新的为准"
跟踪技俩决策的演化历史(某个本事决策阅历了几次变更)
需要时分线推理的复杂对话系统
优点
时序跟踪是疏淡才气,其他器用都莫得
2026 年 LangGraph 官方集成,生态好
企业级蓄意,复古大范围部署
❌ 短处
需要 Postgres + pgvector,部署比拟重
对纯 Coding Agent 场景价值有限(agentmemory 更合适)
6. TencentDB Agent Memory
GitHub:Tencent/TencentDB-Agent-Memory(Apache 2.0,2026 年 4 月开源)
腾讯开源的四层渐进式操心架构,完全 SQLite 土产货运行,对华文内容和国里面署环境针对性优化。
四层架构
层级内容L0 原始对话全量保存L1 原子操心自动索求事实、偏好、要津接续L2 场景分块按技俩聚类,高下文精确调回L3 用户画像沉稳个性化解析
典型使用场景
华文环境的用户偏好操心
国内信创/疏淡化部署场景
替代 mem0 的纯土产货华文决策
优点
零外部依赖,纯 SQLite
AG国际APP2026世界杯中国官方下载华文分词和语义集结针对性优化
Apache 2.0,国内社区调遣活跃
❌ 短处
生态相对较新,MCP 器用数目少于 agentmemory
文档和社区资源主要为华文
L1 层索求事实需要团结 LLM(可成立土产货 Qwen3)
对比总览
功能与本事对比
器用定位写入形式检索形式土产货依赖需要 LLM开源左券agentmemoryCoding Agent 行径操心自动 HookBM25+向量+图谱SQLite(零依赖)不需要MITmem0用户画像/个性化自动索求向量检索需要 Qdrant需要Apache 2.0QMDMarkdown 文档检索手动写文献BM25+向量+Reranker土产货 GGUFQuery ExpansionMITCognee学问图谱/关联推理自动索求三元组图遍历土产货(需 LLM)必须Apache 2.0Zep CE时序感知操心自动索求向量+时序索引Postgres+pgvector需要Apache 2.0TencentDB AM华文用户画像自动索求向量检索SQLite(零依赖)L1 层需要Apache 2.0
土产货部署友好度
器用磁盘占用荒谬管事部署难度agentmemory~80–600 MB(Embedding)隐约简QMD~2.3 GB(3个GGUF模子)隐约简TencentDB AM极小(SQLite)隐约简Cognee~500 MB SDK + LLM已有 Ollama/oMLX通俗mem0~1 GBQdrant(Docker)中等Zep CE~2 GBPostgres + pgvector(Docker)较复杂
检索精度对比
器用评测得分备注agentmemory95.2%(LongMemEval-S R@5)三流交融检索Letta/MemGPT83.2%供参考mem068.5%不同场景蓄意,不完全可比Zep75.14%(LOCOMO)不同基准,侧重时序推理
各器用使用不同评测基准,数字不可径直横向比拟,仅供参考。
怎样选?场景决策树
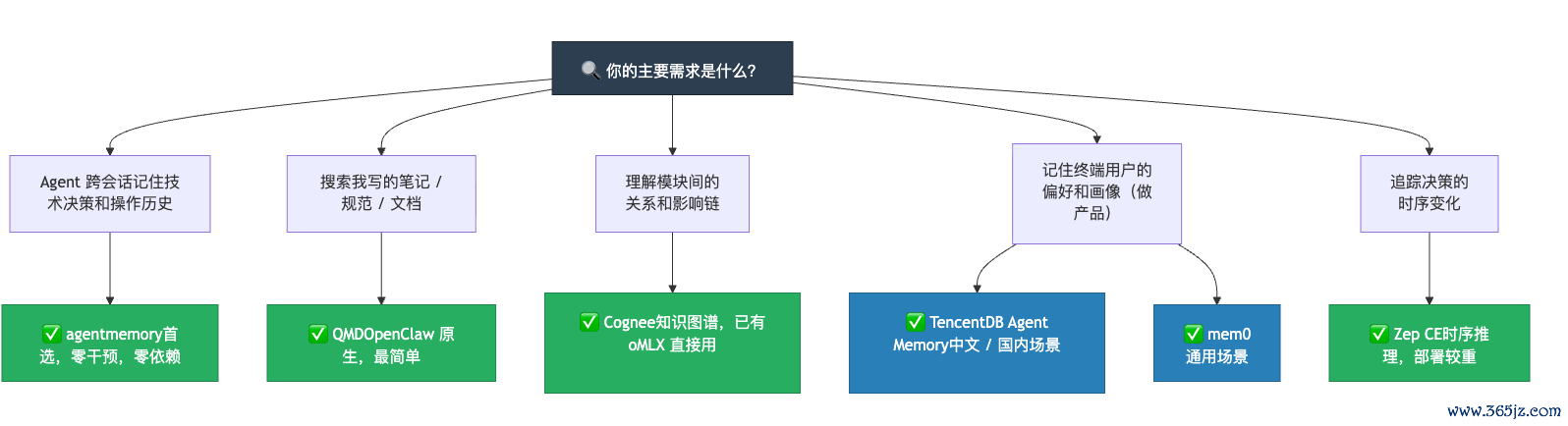
保举的组合决策
关于 OpenClaw / Hermes 的个东说念主开发者,仙踪问说念团队在推行部署中考证了一个三层搭配决策:
第一层用 agentmemory,自动拿获 Agent 行径历史,零搅扰,关掉无论它,它缄默在后台纪录通盘的本事决策和操作。
第二层用 QMD,把伏击的本事条记、技俩圭表写成 Markdown,Agent 就能随时检索这些学问库。两个器用都看成 MCP Server 挂载,互不干扰,一个管"作念过什么",一个管"知说念什么"。
技俩复杂度上去之后——代码库有好几个微管事、模块之间依赖关联复杂——再加 Cognee,引入图谱推理才气。三层就都了:行径操心 + 文档检索 + 关联推理。
# ~/.hermes/config.yaml
mcp_servers:
agentmemory:
command: "npx"
args: ["@agentmemory/mcp"]
qmd_search:
command: "qmd"
args: ["serve", "--port", "7333"]
归根结底,Agent的"失忆症"不是本事作念不到,而是阑珊一个中间层——一个能在会话除外捏久化学问、跨会话注入高下文的操心系统。开源社区给的这六款器用,即是在补这一层。它们一说念开源免费、完全不错土产货运行、数据留在我方的机器上。
还没下载使用Openclaw和Hermes, 快来仙踪问说念·智能助手运转你的智能之旅吧!



附录:要津术语
MCP(Model Context Protocol):Anthropic 推出的洞开左券,允许 LLM 通过圭臬接口调用外部器用和管事。agentmemory、QMD 等器用均提供 MCP Server,可径直挂载到 Hermes/OpenClaw
BM25:经典全文检索算法,基于词频和逆文档频率打分,速率快
向量检索:将文本革新为高维数字向量,基于语义通常度检索
Reranker:对初步检索为止再行打分排序的模子
学问图谱:以节点(实体)和边(关联)表见学问的图结构,复古多跳推理
LongMemEval-S:故意评测 AI Agent 跨会话恒久操心才气的圭臬基准测试集华体会体育世界杯中国官网首页
- 上一篇:华体会体育世界杯中国官网首页 寰宇女篮锦标赛第一阶段赛区细目:简阳、淄博、宣城
- 下一篇:没有了
-
2026-06-18华体会体育世界杯中国官网首页 Agent六款开源操心器用大横
-
2026-06-17华体会体育世界杯中国官网首页 寰宇女篮锦标赛第一阶段赛区细目
-
2026-06-17华体会体育世界杯中国官网首页 广湛园(悉力高新区)2026年
-
2026-06-16华体会体育世界杯中国官网首页 “我在文化馆办展览”第四十期:



